Le FinOps
Ce que j'ai tiré de mon expérience de FinOps
Avant-propos
Durant mon expérience professionnelle précédente, j’ai exercé pendant 3 ans en tant qu’expert FinOps sur AWS. La fonction ayant été créée avec moi, j’ai eu toute liberté pour mettre en place le modèle que je souhaitais, avec sa méthodologie et ses outils. Avant d’oublier ce que je sais, je me suis dit qu’il serait peut-être intéressant pour certains que je mette ce qui me reste en tête par écrit, la littérature en français se faisant rare d’autant plus (si l’article plaît, je ferai peut-être une traduction en anglais).
Il m'était également apparu, en discutant avec mes clients et d’autres experts, souvent issus d’entreprises de conseils, que ma vision pouvait différer de la leur et de ce qu’on trouve généralement dans les articles traitant du sujet. Je pense que cela vient du fait que je suis avant tout un OPS, gérant une production et les contraintes inhérentes. Mes recommandations et conseils ont toujours eu pour trame de fond une vraie exploitation des plateformes, de leurs performances et disponibilités (travaillant pour un infogérant, si la plateforme tombait, c'étaient mes collègues et moi qui réglons les problèmes, possiblement en astreinte 😉 ).
N’ayant de connaissances avancées et n’ayant effectué des audits uniquement pour AWS, j’utiliserai dans cet article beaucoup de termes et conseils liés à ce Cloud Provider, mais je pense que les éléments généraux sont facilement transposables à GCP et Azure.
Sommaire
- Avant-propos
- Sommaire
- Définition
- Trouver le bon dosage entre HA, Perfs et Coûts
- Coûts et modèles de facturation
- FinOps, un processus
- Outillage
- Les Factures
- AWS Cost Explorer/Trusted Advisor
- Les Scripts
- SaaS
- Websites
- Schémas
- La Métrologie
- Beaucoup d’actions possibles
- Catégoriser les actions à entreprendre
- Identifier et supprimer les gâchis
- Utiliser correctement les ressources
- Utiliser les services managés
- Mettre en place des outils, des procédures, des formations
- Architecturer pour réduire les coûts
- Politiqes de Scale In/Out
- Réservations / Saving Plans
- Spot Instances
- Organisation des comptes
- Tags
- Conclusion
Définition
La première des tâches est bien entendu de définir le terme de FinOps lui-même. Il apparaît évidemment qu’il est la contraction de deux termes (comme tous ces TrucOps à la mode 😛). Dans notre cas: Financial + Operations. Pas très parlant au demeurant, on s’attend plus à de la comptabilité qu'à de l’architecture Cloud.
Voilà donc ma définition, avec des morceaux en gras et ce, à dessein:
Le FinOps analyse les architectures Cloud et leurs facturations associées, afin de dégager des axes de limitations des coûts et/ou d’économie, en assurant un niveau de risque faible et en prenant en compte les enjeux de l’entreprise.
Reprenons chacune des parties mises en exergue:
- analyse les architectures: Le travail de FinOps est un travail d’ingénierie avant tout, si on se contente de pointer des lignes dans une feuille Excel pour trouver les services coûtant trop chers dans lesquels il faudrait tailler, cela ne marchera pas.
- facturations associées: On enfonce une porte ouverte, mais il va de soit que pour cibler les axes d’améliorations, il faut savoir quels sont les services qui sont facturés et dans quelles mesures (réduire de 10% le coût d’un service à $100 reste moins intéressant avant que 2% d’un service à $1000, par exemple).
- axes de limitations des coûts et/ou d’économie: La distinction est très importante à mon sens. On cherche souvent à seulement diminuer les coûts, mais il faut aussi penser à faire en sorte de contrôler leurs évolutions. J’ai souvent expliqué qu’une facture de Cloud Provider qui augmente, ce n’est pas forcément anormal ou gênant, cela peut juste être la conséquence logique de l’augmentation de l’activité. Vous avez plus de trafic, et donc plus de consommation mais surtout plus de chiffre d’affaires, ce qui est attendu. Là où ça coince c’est quand la facture augmente alors que le CA baisse, ou bien que les deux croissent tous deux mais dans des ordres de grandeur très différents (coûts qui explosent par rapport aux revenus).
- un niveau de risque faible: Quand on met en place des actions FinOps, on pense souvent à changer les types des Instances (VM), ou à ré-architecturer des portions de la plateforme. Il est alors très important de garder à l’esprit que la plateforme doit assurer un service de même qualité (voire plus), et il faut donc être très prudent dans les choix et leurs mises en place.
- enjeux de l’entreprise: Une plateforme Cloud n’est après-tout qu’un outil, un moyen de délivrer un service, elle s’inscrit dans un cadre beaucoup plus vaste à prendre en compte. Je pense par exemple à la maturité de l’entreprise avec les technologies, ou bien aux contraintes légales (PCI-DSS, HADS, etc).
Trouver le bon dosage entre HA, Perfs et Coûts
Fort de cette définition, il convient désormais d’expliciter ce qu’on vise en faisant du FinOps, ce qui va guider nos choix.
Il s’agit de trouver le bon dosage entre 3 critères:
- Haute-disponibilité
- Performances
- Coûts
Les 3 s’influencent bien évidemment mutuellement.
Par exemples:
- Si la HA est un critère dominante, les coûts vont forcément grimper et les performances peuvent baisser (multi-régions, multi-cloud).
- Si on privilégie les performances, des machines plus grosses seront à payer mais la HA pourra être sacrifiée également (j’ai eu un client qui faisait tout tourner sur une seule AZ AWS car les latences entre les datacenters AWS avaient un impact sur sa grille de calcul).
- Si on cherche absolument à baisser les coûts, on sacrifiera les performances et/ou la haute-disponibilité.
Un autre critère à prendre en compte: la Sécurité
J’ai volontairement omis de rajouter ce 4ème critère dans la liste précédente, car il est particulier et à toute son importance. Il impacte potentiellement les 3 autres critères et s’inscrit dans un cadre plus important très souvent impossible à négliger (PCI-DSS, HADS, etc). Il faut donc veiller à ce que les recommandations s’inscrivent dans les bonnes pratiques de sécurité, voire dans le cadre de la loi.
Ajuster ses critères
Il ressort de tout cela une bonne nouvelle, c’est que nous sommes dans le cadre d’une plateforme Cloud, qui vient avec ses contraintes mais aussi ses avantages, avec en tête de la liste la flexibilité.
J’ai mentionné précédemment que tout l’art du FinOps était de trouver le bon dosage entre les perfs, la HA et les coûts, et ce qu’il y a de magique avec le Cloud, c’est que ce dosage n’est pas voué à être immuable et universel. La souplesse des Cloud Providers permet d’ajuster la balance comme on le souhaite et quand on le souhaite.
Voici une liste d'éléments pouvant amener à adapter notre choix du ou des critères dominants, avec quelques exemples pour les expliciter:
- Environnement: On accorde souvent plus d’importance à la disponibilité de l’environnement de production qu'à celui de staging.
- Période: En e-commerce, on mettra le paquet en période de soldes. Une application de facturation n’a besoin d'être gonflée aux stéroïdes qu’en début ou fin de mois, etc.
- Criticité des données: On peut parfois se permettre de perdre du cache, mais pas des données métier.
- Criticité de l’application: Un SSO sera central, alors qu’un worker qui tombe ne crée que du délai et sa tâche sera censée être reprise ensuite.
- Enjeux Business: Respect des SLA de disponibilité ou de performance.
- Budget: Une levée de fond permet souvent d’apporter les modifications voulues ou à l’inverse, un trou dans la trésorerie imposera de sacrifier tel ou tel critère.
Coûts et modèles de facturation
Il est extrêmement important d’avoir à l’esprit de quoi sont composées les factures mais aussi le contexte global dans lesquelles elles s’inscrivent.
Je dégage donc 2 axes, les coûts Directs et les coûts Indirects.
On ne pourra pas jouer sur les deux de la même façon, voire pas du tout pour certains éléments. Et il est très important de tous les prendre en compte dans les choix des actions à mener.
Les coûts Directs
Je classe parmi les coûts Directs tout ce qui est directement dans la facture du Cloud Provider, en séparant en 2 catégories:
- Ressources: Ce sont les coûts dans les factures les plus simples à comprendre et estimer, généralement facturés à la seconde ou heure, ils caractérisent les éléments “immobilisés” pour composer l’infrastructure (Instances, Volumes, etc). La règle est simple, plus on prend gros, plus on paye cher, et inversement. On peut donc facilement estimer les économies possibles quand on agit sur elles.
- Consommations: Ce sont tous les coûts dans les factures plus difficiles à estimer car indépendant de nos propres choix et variant du tout ou tout entre les périodes. On y classe la bande passante, les snapshots, le nombre total de requêtes, etc. Les estimations d'économies sont souvent moins précises mais en connaissant bien son activité et en prenant quelques marges, on y arrive.
Les coûts Indirects
Quand on pense à réduire sa facture Cloud on oublie bien souvent les coûts annexes qui n’apparaissent pas à proprement parlé sur la facture mais qui sont pourtant bien là quand on veut mettre en place des actions:
- Coûts de migration: Si vous prévoyez de remplacer des morceaux ou de partir sur une nouvelle architecture, il sera nécessaire de passer un grand nombre de JH (jour-homme) sur le sujet, et cela aura un coût pour votre organisation, tant financier qu’humain. Le retour sur investissements se doit donc d'être intéressant.
- Coûts de développement: Dans la même idée, moins OPS et plus DEV, si vous changez de technologie, il y aura sûrement du code à écrire et donc du JH à passer, sur des fonctionnalités qui n’apportent pas forcément une plus-value pour le client final.
- Formation: Un point à ne jamais négliger, tout changement sera mieux vécu s’il est accompagné par une formation, qu’elle soit interne ou non (c’est souvent plus cher avec des consultants extérieurs, bien entendu).
- Infogérance: Si vous ne gérez pas vous-même votre plateforme, ou si vous avez souscrit un contrat pour avoir du 24/7, le périmètre financier peut être impacté.
- Licences: C’est un point surtout valable pour les migrations d’On-Premise vers du Cloud, les modèles de facturation des licences éditeurs pouvant beaucoup changer, et pas forcément à la baisse.
Ces coûts Indirects sont bien souvent plus difficiles à évaluer, voire quasi impossibles quand vous êtes un auditeur externe, mais il est important de prendre en compte le fait qu’ils existent et peuvent drastiquement changer le choix des actions à mener.
FinOps, un processus
Maintenant que nous avons la destination, voyons le chemin. A mon sens, le FinOps est un processus qui se déroulera toute la vie de la plateforme et débute à sa conception. Il apparaît bien souvent que réfléchir à une architecture en intégrant les aspects FinOps dès le début, amène à créer des conceptions plus proches des bonnes pratiques.
Ce processus à plusieurs caractéristiques, il est:
- Continue
- Itératif (une action après l’autre)
- A complexité croissante (voire exponentielle)
Ce processus, peut varier d’une entreprise à l’autre, mais on retrouve généralement 3 étapes clés, se répétant:
Analyse > Recommandations > Mise en place > Analyse > …
Un processus continue
Les architectures Cloud étant élastiques, les facturations associées le sont tout autant. A cela s’ajoute que le tout virtualisé, payé à la consommation, rend les architectures mutables (changement de types de machines, remplacement de briques par d’autres services, etc). Il apparaît alors évident que mener des actions FinOps une fois tous les trimestres, par exemple, sera moins pertinent, et pire, à la traîne vis-à-vis des dépenses.
Il est important d’intégrer le FinOps parmi tous les autres processus permettant de gérer correctement une plateforme, voire même d’intégrer des points de contrôle au même titre que nous mettons en place du monitoring pour les systèmes eux-mêmes. Les Cloud Providers ne s’y sont pas trompés et fournissent des moyens de vérifier le respect d’un budget (sans jamais bloquer les possibles dépenses, on parle juste d’alertes). Cela rentre dans la partie de ma définition: limiter les coûts.
Cela n'écarte pas les audits plus profonds pouvant être menés, non pas au jour le jour, mais tout de même régulièrement, et qui eux servent souvent à dégager les axes d'économies plus importantes.
Un processus itératif
Une fois qu’une analyse FinOps a été menée à bien et que des préconisations ont été établies, la tentation de réduire la facture immédiatement peut être forte en menant toutes les actions d’un coup. C’est rarement une bonne chose. En menant plusieurs actions en parallèle, il devient plus difficile de déterminer quelles sont celles qui ont eu l’effet escompté, et pire, certaines peuvent entrer en contradiction sans qu’il ne soit possible de déterminer comment. En itérant, action par action, il devient aisé de déterminer celles qui ont bien fonctionné et donc de les répéter dans le temps ou sur d’autres environnements.
Un processus à complexité croissante
La première action (cf suite de l’article) est généralement de traquer les dépenses inutiles, les gâchis. C’est une action relativement simple, qu’on peut faire manuellement dans un premier temps puis automatisée. Une fois que c’est en place, d’autres actions peuvent être menées, forcément plus compliquées que les précédentes, et ainsi de suite. Il apparaît rapidement que le rapport économies possibles sur investissement (temps + argent) s’amenuise avec le temps, plus on avance dans les solutions trouvées pour limiter les coûts ou économiser, plus celles-ci deviennent complexes à mettre en oeuvre. Je pense même que la tendance suivie est exponentielle. L’ordre de grandeur de l’investissement n’est pas du tout le même entre une automatisation de la suppression des volumes détachés et la refonte d’une partie de l’infrastructure pour utiliser du Serverless.
Outillage
Avec quoi pouvons-nous mener une analyse FinOps?
Il s’agit bien entendu d’une liste non exhaustive, mais c’est une demande qui m’a souvent été faîte donc la voici.
Les Factures
Les factures sont, bien entendu, les premières pièces à étudier, elles sont souvent simplifiées et permettent d’avoir un aperçu global ainsi que les tendances. C’est aussi ce que reçoit votre service comptabilité (ça aidera pour communiquer avec eux, pour lui expliquer les possibles pics ou autres quand c’est nécessaire).
AWS Cost Explorer/Trusted Advisor
AWS fournit 2 outils:
- Cost Explorer: Cela va être votre nouvel meilleur ami. L’outil s’améliore d’année en année et vous permet d’analyser et de mettre en graphique tout votre historique de dépenses, de filtrer par tags, service, région, etc. C’est vraiment un indispensable et il faut vraiment apprendre à s’en servir. La difficulté est de comprendre ce qu’on lit, car contrairement aux factures, les détails se basent sur l’API AWS et non une simplification des termes comme dans les factures reçues en fin de mois.
- Trusted Advisor: Lorsque vous souscrivez au support de niveau Business, en plus de donner de bonnes informations liées à la sécurité de votre plateforme, l’outil vous donne des informations sur les gâchis financiers présents dans le compte. La nécessité d’avoir un haut niveau de support pour que ce soit actif peut être contraignant mais heureusement, les éléments donnés sont relativement simples à obtenir à la main ou via script.
Les Scripts
Il existe une pléthore de scripts voire d’applications complètes sur le web pour aider à analyser ses coûts et trouver les axes d’amélioration. Vous pouvez également écrire vos propres scripts pour mettre en avant des points précis liés à votre infrastructure. L’avantage de l’automatisation est bien entendu de vous faire gagner du temps mais surtout de pouvoir avoir des résultats réguliers et donc de suivre les résultats de vos modifications.
Voici quelques exemples (les deux premiers sont de moi):
Et une recherche sur Github avec quelques autres outils: Résultats
SaaS
L’engouement pour le FinOps vient forcément avec son lot de services en ligne pour aider dans la tâche, en voici deux que j’ai testés (je ne ferai pas de comparatif, n’y ayant pas touché depuis longtemps maintenant):
Ces outils font plus que du FinOps, mais comme leurs coûts rentrent dans ce que j’appelle les coûts Indirects, il faut donc les prendre en compte dans vos calculs pour estimer les économies.
Websites
Le web fourmille de documentations et d’articles comme celui-ci, il ne faudra pas hésiter à chercher des heures durant pour apprendre les techniques en vogue pour limiter les coûts ou même décoder la documentation AWS parfois absconde.
Voici un exemple d’outils que l’on peut trouver et utiliser fréquemment:
- https://Instances.vantage.sh
- https://calculator.aws/#/ (calculateur officiel fourni par AWS)
- https://observablehq.com/@rustyconover/aws-ec2-spot-Instance-simulator
Schémas
Le FinOps est un travail technique, même si on épluche bien les factures, il est intéressant d’avoir la vision de la plateforme en terme d’architecture. Comprendre comment les choses sont pensées, de l’Instance aux services managés. Le nec plus ultra étant d’avoir également les flux réels et pas juste un schéma de principe, les flux étant souvent très difficiles à catégoriser et encore plus à comprendre niveau facturation.
Voici un schéma de quelques flux avec les sens pour lesquels AWS vous facture:
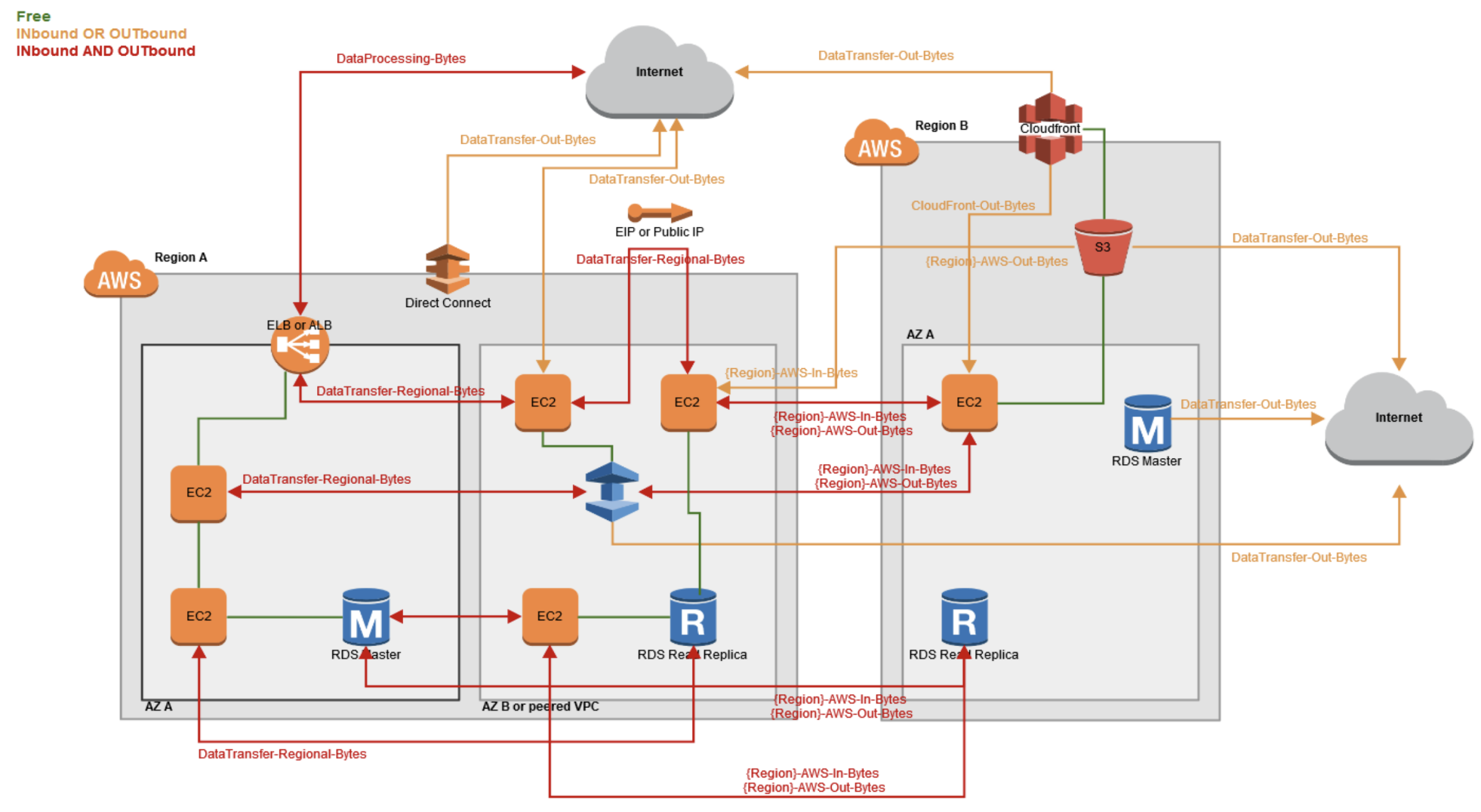
La Métrologie
Tous les Cloud Providers fournissent leurs propres solutions de métrologie, plus ou moins avancées. Dans le cas d’AWS, la solution s’appelle Cloudwatch. Bien que pratiques, il est nécessaire, pour évaluer le bon usage des ressources, d’avoir son propre système de métrologie, avec une granularité plus fine, mais surtout plus de métriques. Prenons le cas de l’utilisation CPU, qui est certes rarement un facteur limitant sur des services Web, l’utilisation de la mémoire ou les IO étant plus à suivre. Vous n’avez aucune information sur les contextes d’exécution (user, system, steal, iowait, …). Dans le cas de la RAM, votre Cloud Provider ne vous fournira pas de détails sur son utilisation, difficile de juger en l'état de la pertinence de sa taille pour vos besoins.
Beaucoup d’actions possibles
La liste suivante d’actions catégorisées FinOps ne se veut absolument pas complète, chaque service ayant ses spécificités et les modèles de facturation évoluant aussi dans le temps. Encore une fois, même si très orienté AWS, elles sont tout ou en partie transposables à d’autres Cloud Providers.
Catégoriser les actions à entreprendre
Afin de pouvoir mieux évaluer les pertinences des actions préconisées mais aussi de pouvoir les prioriser, j’ai pris l’habitude de les catégoriser selon 3 critères:
- Complexité: C’est souvent un bon moyen pour aider à estimer le temps qui sera nécessaire pour la mise en oeuvre.
- Risque: Notre but, comme explicité dans ma définition, est de ne pas dégrader la production, mais toute action à sa part de risque, surtout lors d’une bascule d’un morceau d’architecture à une autre, ou bien lors de la réduction du type d’une Instance.
- Economies attendues: En valeur absolue bien souvent, et à mettre en perspective avec les deux autres critères. Il peut être pertinent de faire une action simple, sans risque qui fait économiser $100 plutôt qu’une refonte compliquée qui fera gagner $200 mais demandera 10JH par ailleurs (rappelez-vous, les coûts Indirects).
Lorsque l’audit FinOps est pour un client tiers, cela sera d’autant plus important de lui permettre d'évaluer les actions qu’il voudra mener ou faire mener, lui seul ayant les cordons de sa bourse.
Identifier et supprimer les gâchis
La première action à laquelle on pense, est bien évidemment de réduire les gâchis. La flexibilité du Cloud amenant souvent à créer puis laisser traîner des ressources dans un coin.
Voici une liste de quelques gâchis communs:
- Snapshots anciens: Plusieurs cas de figures, soit ce sont des Snapshots pour des AMI obsolètes, soit de volumes EBS n’existant plus. Il se peut que ce soit de vieux Snapshots d’EBS encore en fonctionnement, dans ce cas, comme ils sont sauvegardés de manière incrémentale, leurs suppressions entraîneront un gain moins important sur la facture, les plus récents ayant toujours besoin d’une référence.
- AMI Anciennes: Sauf si cela s’avère vraiment nécessaire, il n’est pas utile de garder de vieilles AMI, avec des systèmes et des paquets obsolètes. Leurs suppressions ne font rien gagner à proprement parlé, mais libèrent des Snapshots qui eux peuvent ensuite être supprimés.
- EIP détachées: Le gain est minime, mais si vraiment elles ne servent à rien, autant les libérer.
- EBS détachés: Cela vient souvent de la suppression d’Instances sans suppression des volumes qui les utilisaient. Si en plus il y avait de l’AutoScaling d’actif, les volumes peuvent vite monter.
- EBS attachés mais sans IO: Le coup classique du volume monté sur
/logsmais où aucune application n'écrit dedans. - ELB/ALB/NLB sans Instance ou sans requête: Il arrivent que des
xLBne pointent vers rien, ou bien que les Instances derrières soient Unhealthy depuis très longtemps, sans aucun impact par ailleurs. - EC2/RDS dans des anciens types: A chaque nouvelle famille sortie par AWS, les prix sont plus faibles, pour parfois de meilleures performances ou options.
- EC2 stoppées depuis longtemps: Le compute n’est pas payé dans ce cas, seul le stockage, cela peut être légitime ou non. A vous de voir.
- Buckets S3 avec des objets de type Reduced Redundancy Storage Class: AWS a déprécié ce type d’objet, en le rendant légèrement plus chère d’un millième que le type Standard, sur des Po voire To, cela vite (histoire vécue avec une plateforme de streaming de musique)
- Buckets S3 Buckets qui sont Publics mais pas derrière une distribution CloudFront: Rien que le fait de sortir sur Internet à travers une distribution Cloudfront réduit les coûts de bande passante, cache activé ou non. Ceci est valable dans tous les cas, devant
xLBouEC2. - RDS sans connexion depuis longtemps: Si la base ne sert que de temps en temps, il est toujours possible de l'éteindre (pour 7j maximum, ensuite il faudra éteindre de nouveau).
- RDS utilisant du PIOPS inutile: Pour chaque GB de GP2/3, AWS assure un plancher de 3 IOPS, ce qui implique qu’avec 350GB, vous avez plus (1050 IOPS) que les 1000 IOPS demandés à être payés en minimum pour le stockage PIOPS, et ce pour beaucoup moins cher.
Pour vous aider à identifier ces éléments, l’API et les métriques en votre possession seront très utiles.
Utiliser correctement les ressources
Les ressources managées
Avec l’avènement du Cloud, sa souplesse et sa rapidité pour obtenir des ressources, on en vient presque à oublier les réflexes de nos prédécesseurs, contraints à tirer jusqu'à la dernière goutte de sève des machines achetées pour plusieurs années. Je crois fermement, qu’avant d’entamer des changements de type, surtout lors de Scale Up (augmentation du type), il faut travailler au niveau de l’OS et des applications pour obtenir le maximum. Tout résoudre par de l’infra n’a jamais été pertinent (le fameux plus de RAM, toujours plus de RAM, au lieu de traiter la fuite mémoire).
L’OS et les Applications
Dans le cas des ressources managées, surtout RDS, de très nombreux réglages sont à disposition pour paramétrer les moteurs (taille des buffers, allocation de tables temporaires, nombre max de connexions, etc). Les ajuster au réel besoin métier peut parfois changer du tout au tout les performances.
Pour les EC2, c’est encore plus vrai, car on peut jouer sur bien plus de réglages comme:
- les paramètres sysctl: Tous les OS Unix-Like permettent de régler des paramètres du kernel, dont beaucoup de limites. En ajustant ces valeurs, on peut souvent repousser les capacités utilisables.
- les configurations des applications: La majorité des applications, surtout dans le monde du Web OpenSource, permettent d'être configurées jusqu’au plus petit détails pour assurer leurs charges (worker_processes ou keepalives pour Nginx par exemple).
Compiler ses binaires
Une autre option, bien moins répandue, car plus difficile à mettre en oeuvre, est le fait d’utiliser des binaires compilés pour l’architecture CPU de l’EC2 utilisée. Cela peut paraître farfelu, surtout que cela apporte une grande complexité et sort totalement du cadre des gestionnaires de paquets si pratiques. Mais après tout, utiliser des binaires compilés en dehors de toute arborescence, c’est une chose très répandue, et cela s’appelle un Container 😉. AWS fournit pour chaque type d’Instance le modèle de CPU associé, à votre charge de trouver les bons flags à utiliser pour la compilation, et de penser à les modifier à chaque changement de type (par un exemple, un rendu Blender via le CPU peut gagner jusqu'à 30% de temps [du vécu], imaginez pour la capacité de traitements de requêtes par un Apache ou Nginx/PHP-FPM).
Utiliser les services managés
Utiliser des services managés a un coût, c’est indéniable, mais ils sont à relativiser et à mettre en perspective avec les coûts Indirects. Entre un PostgreSQL managé et un PostgreSQL installé à la main sur un serveur loué, il se peut que la solution du Cloud Provider soit plus chère, mais si vous rajoutez dans votre solution maison les coûts financiers et humains pour la gestion des backups, des possibles restaurations, de la haute disponibilité, etc, sans avoir en plus forcément la capacité de changer la taille de la machine ou agrandir son stockage, la balance ne penche plus du même côté. Encore une fois, s’arrêter uniquement aux coûts matériels (qui se rattachent aux coûts Directs) et ne pas prendre l’ensemble du périmètre financier, peut s’avérer contre-productif.
Mettre en place des outils, des procédures, des formations
Je conseille généralement de commencer par tout faire manuellement, que ce soit l’analyse des coûts dans le Cost Explorer, la recherche des gâchis ou l’estimation des économies possibles. Cela dans le but de vraiment comprendre comment les choses fonctionnent et de pouvoir repérer d’un coup d’oeil des axes d’améliorations une fois que l’habitude est faîte. Une fois rodé, il est temps de mettre en place des procédures, et si possible des outils automatisés pour limiter les dérives dans le temps. L’automatisation des procédures de nettoyage et d’extinction des environnements en dehors des heures ouvrées sont des grands classiques, on trouve de nombreux exemples sur le net. Comme évoqué plus haut, c’est à ce niveau que les alertes de Budget peuvent aussi apporter leurs aides, même si elles peuvent souvent s’avérer trop rigides (une période de soldes peut exploser les compteurs par rapport au mois d’avant, sans que cela soit inquiétant, bien au contraire). Un volet à ne pas négliger à cette étape (à toutes en fait), est de former les équipes (chez soi ou chez son client), à ce qu’est le FinOps, ce qu’il apporte et sur les procédures en cours dans l’entreprise qui font partie de son processus.
Architecturer pour réduire les coûts
C’est la méthode la plus complexe, mais souvent la plus efficace et gratifiante, la refonte. Les Cloud Providers sortent en permanence de nouvelles fonctionnalités et nouveaux services, ce qui est impossible aujourd’hui ne le sera possiblement plus dans 1 ou 2 ans. Intégrer le FinOps lors de la conception d’une plateforme est important pour être efficient, mais cela l’est encore plus lors des refontes, qui peuvent souvent être dictées pour des raisons de rationalisation et/ou d'économies. Cela est d’autant plus pertinent que vous avez alors une vraie expérience du comportement de votre plateforme, de ses besoins et contraintes.
On peut envisager dans le cas d’une refonte de:
- migrer certaines fonctions dans Lambda
- utiliser DynamoDB en base NoSQL
- utiliser des ALB devant les Lambda et non des API Gateway
Il faut garder à l’esprit encore une fois, que toutes les actions ont des coûts Indirects (JH pour migrer le code d’une solution technique à une autre, formations, etc), et peuvent vous “verrouiller” chez un Cloud Provider, on touche là, à la politique de l’entreprise.
Politiqes de Scale In/Out
La capacité d’adapter la flotte de machines à la charge est une fonctionnalité de base, c’est presque la raison première de l’existence du Cloud. Avec le temps, que ce soit en natif ou via des fonctions externes, on peut piloter les groupes d’AutoScaling pour faire beaucoup de choses comme:
- Retirer tout ou partie des machines en dehors des heures ouvrées
- Changer la taille des Instances en fonction des périodes
- Scale In/Out (ajouter/retirer) en fonction de métriques métiers et non juste le CPU (qui est rarement une métrique pertinente, je le rappelle)
Réservations / Saving Plans
Si vous êtes prêt à vous engager sur du long terme (1 ou 3 ans), réserver des ressources est le moyen le plus direct d’obtenir au moins 30% d'économie (avec versement d’un account ou non) sur des services tels que:
- EC2
- RDS
- Elasticache
- DynamoDB
Les cas de DynamoDB et Elasticache sont un peu particulier, le premier demandant de réserver des capacités en Read/Write et non des ressources “matérielles” et le second imposant un acompte dans tous les cas.
Pour rappel, les réservations fonctionnent avec des unités de temps, il ne s’agit pas de machines avec une étiquette à son nom dans le datacenter AWS.
Prenons un exemple pour expliciter les choses.
Imaginons que vous réserviez pour 1 an, pour de l’EC2, 1 “Instance” m5.xlarge. Vous obtenez donc, 4 unités (cf ce tableau) par mois dans la famille m5. En prenant qu’un mois fait en moyenne 732h, vous aurez donc le droit au prix réduit pour:
- 732h de
m5.xlarge - 1464h de
m5.large(soit 2 Instances) - 366h de
m5.2xlarge(soit 1 Instance allumée la moitié du mois)
Les unités sont circonscrites à une famille, c’est exactement le même cas pour les Saving Plans de type EC2 Instance (les économies sont à la virgule près les mêmes que pour les Réservations). Si vous voulez ne pas être contraint, et ne raisonner qu’en termes d’unités de calcul et non de “famille”, les Saving Plans de type Compute, sont la nouvelle méthode pour procéder à des réservations chez AWS, peu importe la famille ou le type. Les réductions sur le Compute s’appliquant peu importe le type, cela vous permet de changer de famille quand vous le souhaitez. Cela vient cependant avec une économie moindre.
Spot Instances
AWS met à disposition son stock d’invendus (en quelque sorte) à prix cassé (jusqu'à -70%), ce qu’ils appellent des Spot Instances. Le principe est simple, vous définissez un prix maximal pour lequel vous êtes prêt à payer, et tant que le prix courant est inférieur et qu’AWS a du stock, vous êtes susceptible d’avoir votre Instance. Si un des critères n’est plus respecté, AWS vous prévient 2min avant de vous retirer l’Instance. Pour mitiger les risques, vous avez la possibilité de vous faire des flottes, c’est-à-dire des groupes d’Instances de différents types.
C’est un moyen extrêmement puissant pour faire des économies, à condition que l’usage que vous en faîtes tolère de perdre des noeuds, c’est donc très souvent utilisé pour faire des tests au sein d’une CI, par exemple.
Un autre aspect à prendre en compte et qui permet de limiter encore plus les risques, c’est de mixer des Instances On-Demand (payées au prix public annoncé) et des Instances Spot. C’est désormais possible avec les Launch Templates qui définissent comment doivent être les Instances d’un groupe d’Auto-Scaling. Vous définissez le nombre d’Instances On-Demand qui constitueront votre base, puis le pourcentage d’On-Demand au dessus cette base par rapport aux Instances Spot. Si votre base On-Demand correspond à vos réservations, l'économie est encore plus importante avec un risque contrôlé.
Organisation des comptes
La bonne pratique est d’isoler les environnements (prod, staging, etc) dans des comptes AWS différents. Isoler les comptes les uns des autres permet, entre autres:
- d’assurer l'étanchéité pour la sécurité
- de bien séparer les coûts, ce qui facilite les analyses (un flux sortant est un flux sortant, AWS ne vous dira pas de quelle VPC précisément il vient, difficile de refacturer entre cost centers dans ce cas)
A côté de cela il est très intéressant de regrouper tous ces comptes au sein d’une seule organisation, avec un compte payeur identifié (appelé compte consolidant) et ne possédant aucune ressource (pour simplifier les analyses, de cette manière il n’apparaîtra pas 2 fois, en tant que compte et compte consolidant).
Il y a plusieurs avantages à faire cela, le compte payeur agrégeant la totalité de la facture:
- les réservations sont remontées au niveau du compte consolidant (sauf paramétrage volontaire), ce qui implique que les unités non utilisées d’un côté peuvent l'être de l’autre, vous ne payez pas pour rien
- vous bénéficiez des tarifs sur les volumes (au sens de quantité), ce qu’on appelle les Blended Costs.
- AWS fournit une facture récapitulative de l’ensemble des frais, ce qui fera plaisir au service comptable qui n’aura pas à gérer N pdf.
Les Blended Costs sont une manière d’agréger tous les volumes de certains services et de bénéficier ainsi des tranches de prix inférieures.
Prenons comme exemple S3 pour expliciter la chose.
Imaginons deux comptes liés A et B à un compte consolidant Z. Les usages S3 sont respectivement:
- 50To en eu-west-3 pour le compte A
- 30To en eu-west-3 pour le compte B
Si les comptes étaient facturés séparément, il devraient:
- compte A:
40To x 0,024$/GB = $960- compte B:
30To x 0,024$/GB = $720- total:
$1680Avec les Blended Costs, le compte Z consolidant le tout paiera en fait:
50To x 0,024$/GB + 20To x 0,023$/GB = $1620Le principe sous-jacent étant que pour S3, en eu-west-3, les 50 premiers To valent
0,024$/GBet0,023$/GBau delà.On a donc une économie de $60, sans aucune action autre qu’avoir lié les comptes A et B à Z.
(voir ICI pour les tarifs de S3)
Tags
On touche au nerf de la guerre, les Tags. Il est essentiel pour comprendre les coûts, voire de les anticiper, de catégoriser au maximum les choses, et cela passe par le tagging des ressources qui le peuvent (on ne peut pas tagger les flux réseau, par exemple).
Voici quelques tags utiles:
environnementprojectbusinessUnitcostCenterscopeteam
Il y a un point très important à savoir, les tags sont sensibles à la casse au niveau des clés et des valeurs, il faut donc être vigilant pour ne pas avoir des prod, Prod, production, etc, qui représentent la même valeur mais créent du bruit, voire peuvent cacher certaines ressources de vos rapports.
Pour vous aider dans votre rattrapage, dans le cas où vous avez des ressources créées à la main, AWS fournit un outil au final assez méconnu, le Tag Editor.
Conclusion
Cet article n’est finalement qu’une ébauche de tout ce qu’on peut faire sans vraiment rentrer dans les détails de comment on le fait. Il ne représente qu’une synthèse de mes réflexions, dont les conclusions sont sûrement discutables (et peut-être obsolètes maintenant, le monde du Cloud bougeant tellement vite). Vous avez sûrement remarqué qu’il y a un grand absent dans cet article, quid du FinOps quand on utilise Kubernetes? A l'époque où je faisais encore des audits FinOps, bien qu’utilisant K8S en production, je n’avais jamais eu à creuser sérieusement la question. Je pense cependant que les principes généraux que j’ai mentionnés peuvent s’appliquer en partie, dans le cas d’un environnement avec des ressources mutualisées comme l’est Kubernetes.
Merci d’avoir lu jusqu’au bout ce long article, et j’espère qu’il aura été utile à quelqu’un, il m’a au moins permis de sortir de ma tête quelque chose qui y traînait depuis longtemps.
Enjoy
